MentalBlackboard
Evaluating Spatial Visualization via Mathematical Transformations
Prediction
Predict the final hole configuration after unfolding, given the folding sequence and initial hole properties.
Prediction — Problem
Prediction — Solution
Backward Prediction
Predict final hole configurations when folding actions occur away from the camera, introducing limited visual information.
Backward Prediction — Problem
Backward Prediction — Solution
Abstract
MentalBlackboard is a large-scale, open-ended benchmark designed to evaluate spatial visualization abilities in Vision-Language Models. The benchmark extends paper folding and hole punching tests with symmetry and rotation transformations in a physically grounded 3D environment. It introduces prediction, planning, and generalization tasks across video, image, and text modalities.
Dataset Generation
MentalBlackboard is built with an automated, physically grounded pipeline based on a 3D paper-folding and hole-punching simulation (VPython). Folding, rotation, punching, and unfolding are executed under strict physical constraints to avoid deformation or self-intersection, and the paper is discretized into triangular regions to support diagonal and multi-stage folds.
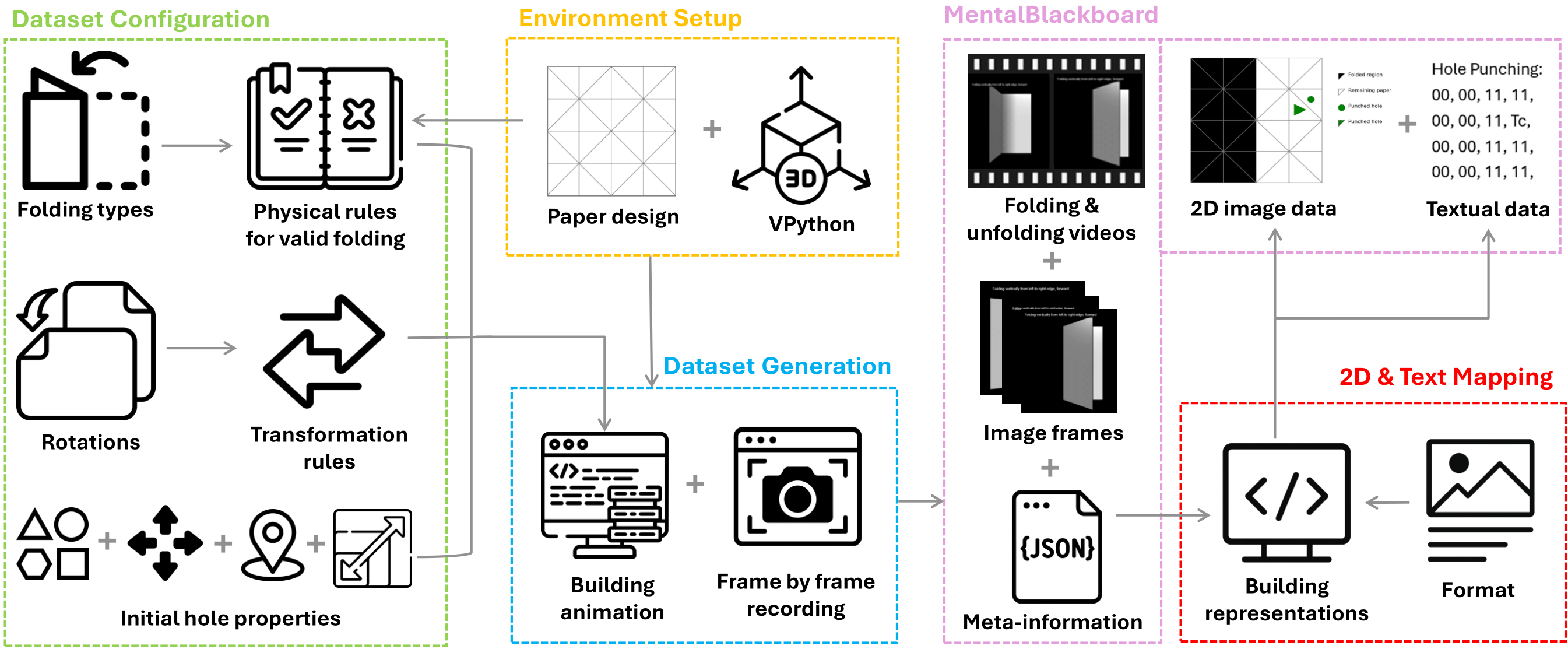
Figure 1: Automated VPython-based pipeline for folding, rotation, punching, and unfolding.
Dataset
MentalBlackboard is an open-ended spatial visualization benchmark built on a physically grounded 3D simulation of paper folding and hole punching. The dataset supports symmetry- and rotation-based transformations and explicitly models the physical changes induced by rotations during folding and unfolding. It enables the generation of over 12K unique folding configurations and more than 1 million potential problem instances.
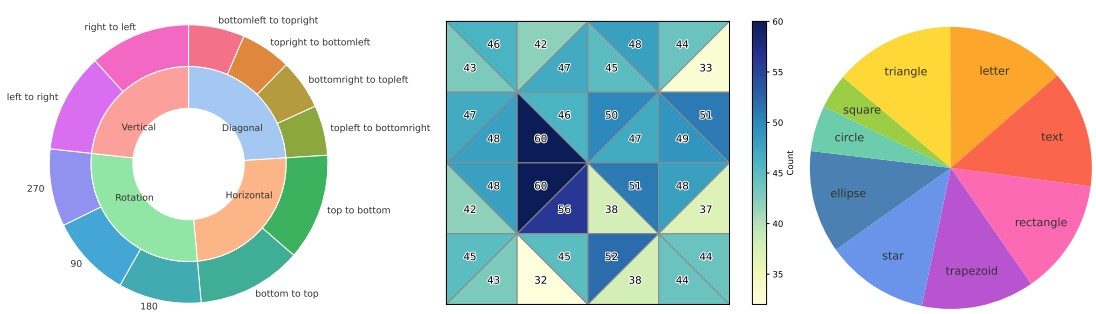
Figure 2: Benchmark statistics of the prediction task. (a) The distribution of the folding and rotation types across four main tasks and eleven sub-tasks. (b) The visualization of the initial hole locations in the paper design. The darker cells represent paper regions with a higher number of punched locations. (c) The distribution of the initial hole shapes across nine categories. Square and circle shapes are excluded from rotation tasks, as their appearance is not affected by rotations.
The benchmark includes two core task settings—Prediction and Planning—spanning video, 2D image, and text-based representations, along with a generalization task that evaluates spatial property transfer across analogous folding scenarios. MentalBlackboard adopts an open-ended evaluation framework to enable fine-grained analysis of spatial reasoning, symmetry application, and sequential mental transformations.
-1.png)
Figure 3: Examples of a prediction task and a planning task.
Evaluation Setup
We evaluate state-of-the-art Vision-Language Models in a zero-shot setting across video-, image-, and text-based prediction tasks, and 2D image-based planning tasks. Performance is measured using Exact Match and a custom Partial Accuracy metric designed for open-ended spatial predictions. Partial Accuracy accounts for both correct hole matches and over-prediction, and is defined as
\( \text{PartialAccuracy} = \frac{M}{G + \max(0, P - G)} \)
where G is the number of ground-truth holes, P is the number of predicted holes, and M is the number of correctly matched holes. Field-wise accuracy is additionally reported for individual hole attributes to enable fine-grained analysis.
Main Results
- State-of-the-art Vision-Language Models (VLMs) struggle with multi-stage symmetry transformations, particularly when reasoning over folded and unfolded paper structures.
- The best-performing models achieve at most 25% exact match accuracy on prediction tasks, with substantially lower performance in image- and video-based settings.
- Planning tasks expose severe limitations in reverse spatial reasoning, with no model exceeding 10% accuracy when inferring folding sequences from final hole patterns.
- Models are consistently more accurate at predicting shape and size than location and direction, indicating difficulties in spatial localization and physical orientation reasoning.
- Tasks involving rotation significantly degrade performance, suggesting limited understanding of the physical changes induced by reorientation.
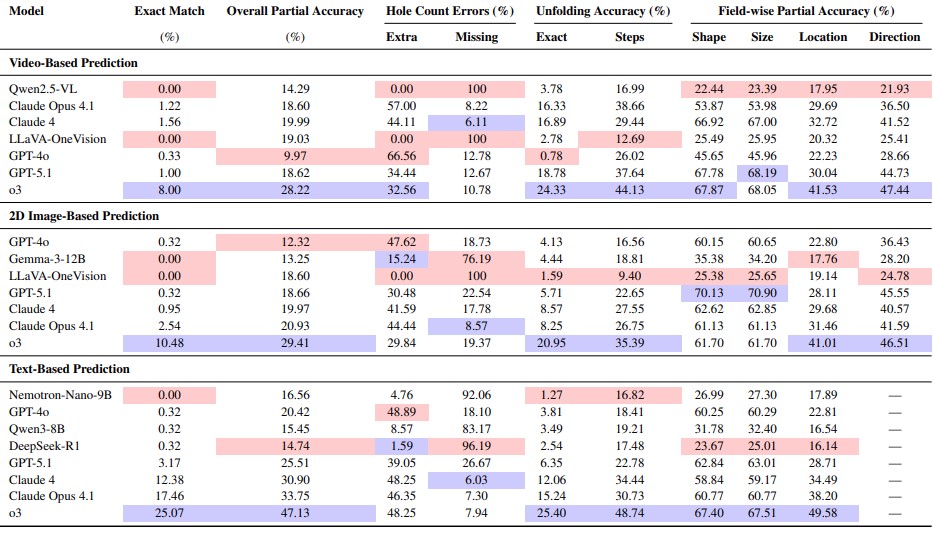
Table 1: Model performances across video-based, 2D image-based, and text-based prediction tasks.
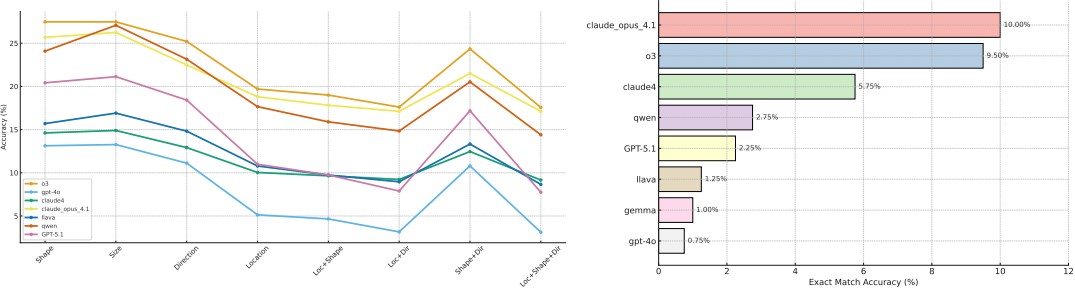
Figure 4: Performance of the models on the planning task: (a) partial accuracy per field; (b) exact match accuracy of baseline models.
Do VLMs Transfer Spatial Information?
This section evaluates spatial knowledge transfer using a generalization task with 240 2D image-based analogy questions across three folding configurations. Each task pairs two scenarios with identical folds but different hole data, requiring models to infer missing hole attributes by relating the two cases.
The task isolates four hole attributes—shape, size, location, and direction—changing only one at a time. It measures spatial transfer rather than full spatial visualization or symmetry reasoning.
-1.png)
Figure 5: An example of a generalization task employs a visual analogical reasoning framework, which requires making an inference from the first scenario to identify the missing part in the second scenario.
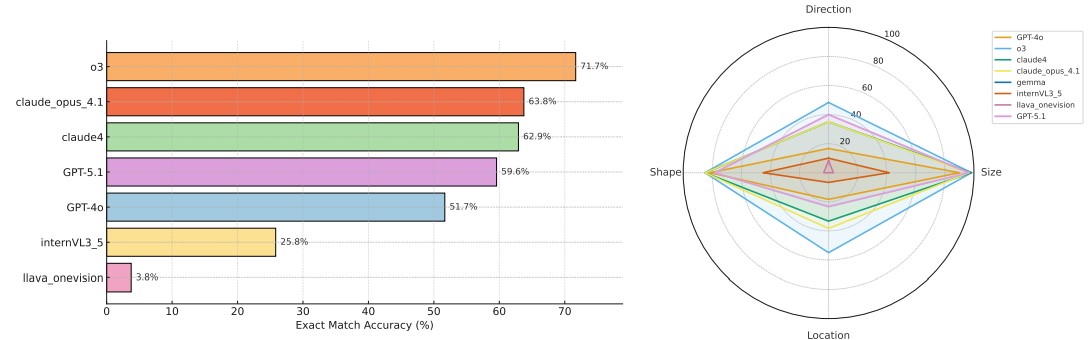
Figure 6: Performance of the models on the generalization task: (a) exact match accuracy of baseline models; (b) the accuracy of the models for each category.
Results show a large gap between proprietary and open-source models. Models perform best on shape and size, while direction and location remain challenging. Overall, models tend to underpredict holes. The identical folding patterns reduce the need for mental unfolding, explaining higher performance than in prediction or planning tasks.
How Do Representations Influence Performance?
This section studies the impact of representation format by comparing text-based, 2D image-based, and video-based PFT prediction tasks after removing the direction attribute. Identical problem instances are used across modalities for fair comparison. Text-based representations generally yield higher accuracy than visual formats, especially for Claude models, which show large drops from text to image/video tasks. In contrast, GPT-4o exhibits nearly identical performance across all modalities, while GPT-5.1 shows only minor variation. These findings indicate that model performance is strongly influenced by input representation, with some models relying more heavily on textual cues than visual ones.

Table 2: Model Prediction Performance across Text, Video, and 2D Image Tasks
How Does Backward Folding Affect Performance?
A backward folding prediction task is introduced using 180 video questions in which folding actions are reversed (away from the camera) while all other visual parameters remain unchanged. The final paper appearance matches that of forward-fold tasks. In the backward folding task, reversing the folding direction while keeping the final paper appearance unchanged reveals clear model differences: o3 maintains performance comparable to forward folding, whereas the Claude models show reduced exact-match accuracy and generate more extra holes. These results indicate that some models, particularly the Claude variants, rely on view-dependent representations and struggle with spatial reasoning when the perspective of folding actions is reversed.
BibTeX
@misc{yilmaz2026mentalblackboardevaluatingspatialvisualization,
title={MentalBlackboard: Evaluating Spatial Visualization via Mathematical Transformations},
author={Nilay Yilmaz and Maitreya Patel and Naga Sai Abhiram Kusumba and Yixuan He and Yezhou Yang},
year={2026},
eprint={2602.19357},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2602.19357},
}